Hugin: tags e resumos para Hugo com IA

Neste post
Quem mantém um blog estático com Hugo sabe que existem duas tarefas que ninguém gosta de fazer: classificar posts com tags e escrever meta descriptions. São aquelas coisas que você pula na hora de publicar porque o post já está pronto, o deploy já está configurado, e ficar escolhendo entre “selfhosted” e “self-hosted” não é exatamente o uso mais nobre do seu tempo. O resultado é previsível: posts sem tags, descriptions vazias ou copiadas do primeiro parágrafo, e uma taxonomia que mais atrapalha do que ajuda.
Eu estava nessa situação com dois blogs — um com quase 400 posts, outro crescendo rápido. Tags inconsistentes, posts sem nenhuma classificação, descriptions genéricas. Ferramentas de IA resolveriam parte do problema, mas nenhuma encaixava no fluxo que eu queria: algo que lesse os posts, sugerisse tags e resumos, mas me deixasse aprovar tudo antes de mexer nos arquivos. Sem surpresas, sem commits automáticos, sem tag inventada que eu nunca usaria.
Então construí o Hugin.
O que é#
Hugin é uma TUI (terminal user interface) em Python que abre um diretório de posts Hugo, lista todos por data de publicação, e oferece duas operações principais: gerar tags e gerar resumos. Nos dois casos, o conteúdo do post é enviado a um LLM, a resposta é normalizada e apresentada para revisão antes de tocar no arquivo.
O nome vem de Huginn, um dos corvos de Odin na mitologia nórdica — o corvo do pensamento, que voa pelo mundo coletando informações e reporta ao dono. Também rima com Hugo, o que não é coincidência.
O problema das tags#
A parte mais irritante de manter tags consistentes em um blog não é criar tags novas — é lembrar quais já existem. Se você tem 400 posts e 60 tags únicas, é questão de tempo até aparecer “selfhosted” em um post e “self-hosted” em outro. Ou “automatização” e “automação” convivendo como se fossem conceitos diferentes.
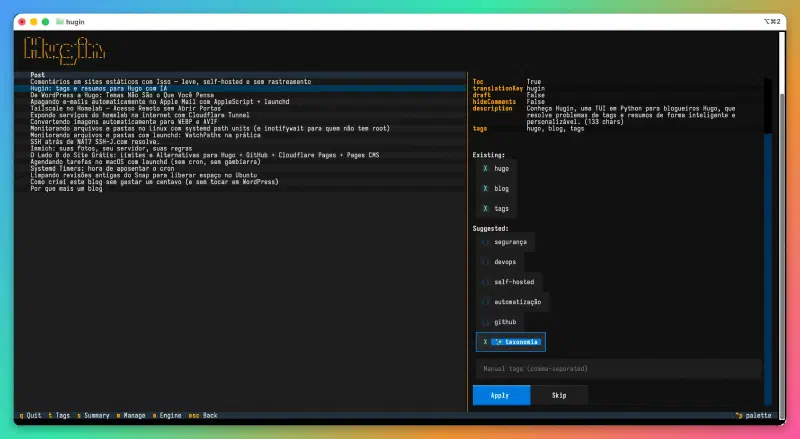
Hugin resolve isso de duas formas. Primeiro, coleta todas as tags existentes no blog e envia ao LLM ordenadas por frequência de uso, com instrução explícita para preferir tags que já existem. Segundo, passa cada tag gerada por um normalizador que aplica lowercase, substitui espaços por hífens, remove artigos e deduplica contra o pool existente. Se o LLM sugerir “O Docker” para um post, o normalizador transforma em “docker” — que provavelmente já está no pool.
Tags novas aparecem marcadas com um indicador visual na interface. Se o LLM sugeriu algo que não existe no blog, você sabe antes de aplicar. E se quiser adicionar tags manualmente — porque às vezes o LLM simplesmente não sugere o óbvio — tem um campo de texto para isso.
O problema dos resumos#
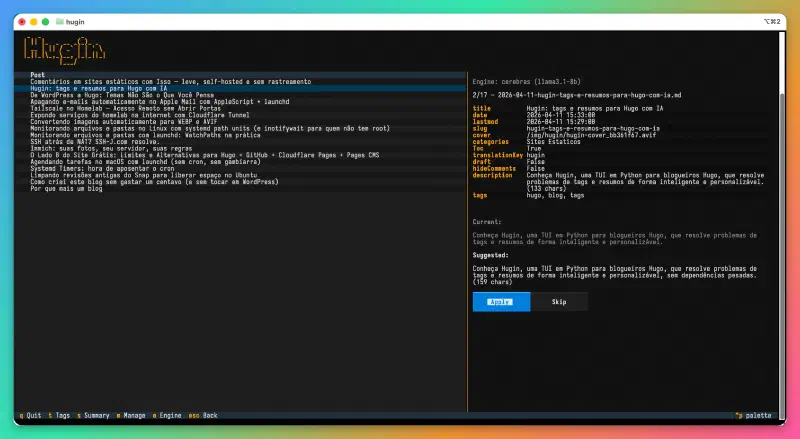
Meta descriptions são aqueles textos de 150 caracteres que aparecem nos resultados de busca. Todo mundo sabe que são importantes, ninguém gosta de escrevê-los. O resultado típico é um description vazio (o Hugo usa os primeiros caracteres do post) ou uma frase genérica que não diz nada sobre o conteúdo.
Hugin gera resumos entre 140 e 160 caracteres, no idioma do post, com uma persona de blogueiro escrevendo sobre seu próprio trabalho — não de redator SEO. Ou seja: nada de “Descubra como…” ou “Aprenda a…”. Se o resumo ficar longo demais, o LLM é automaticamente chamado de novo para encurtar. O resultado aparece com contagem de caracteres ao lado, e só é gravado se você aprovar.
Gerenciamento de tags#
Conforme o blog cresce, a taxonomia precisa de manutenção. Hugin tem uma tela dedicada para isso: uma lista de todas as tags ordenadas por frequência, com operações de renomear, mesclar e excluir. Mesclar é particularmente útil — seleciona a tag de origem, escolhe o destino, e todos os posts são atualizados de uma vez. Se você tem “linux” em 20 posts e “gnu-linux” em 3, resolve em dois toques.
Agnóstico ao modelo#
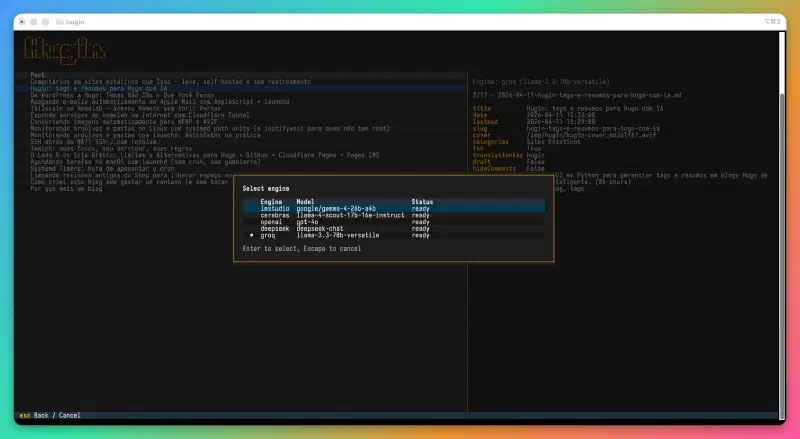
Hugin não depende de nenhum provedor específico de IA. Qualquer endpoint compatível com a API OpenAI funciona: Cerebras, Groq, DeepSeek, OpenAI, LM Studio, Ollama. Os motores são cadastrados em um arquivo TOML simples, e a seleção de engine e modelo é feita direto na interface — inclusive com listagem automática dos modelos disponíveis no endpoint.
Na prática, tenho usado o Cerebras para a maioria dos posts (rápido e barato) e o LM Studio com Gemma local para testes. Trocar entre eles é uma tecla.
Como funciona na prática#
Você abre o Hugin apontando para o diretório de posts:
hugin ~/blog/content/posts
A interface mostra todos os posts em uma tabela navegável. Seleciona um, tecla t para tags ou s para resumo. Um spinner aparece enquanto o LLM trabalha. Quando a resposta chega, as sugestões aparecem com checkboxes — desmarca o que não quer, marca o que quer, aplica. O frontmatter é atualizado, o arquivo é salvo, e você continua para o próximo post.
Nenhum token é gasto até você pedir. Nenhuma alteração é feita até você aprovar.
Stack#
Para quem se interessa pelo lado técnico: Python 3.11+, Textual para a TUI, Click para o CLI, httpx para as chamadas assíncronas ao LLM, python-frontmatter para ler e escrever YAML. Sem banco de dados, sem daemon, sem dependências pesadas.
Código#
O Hugin é open source e está disponível no GitHub. Se você mantém um blog Hugo e está cansado de classificar posts manualmente, talvez ele resolva o seu problema também.
Repositório: github.com/janiosarmento/hugin
Sysadmin, 53 anos, brasileiro trabalhando de casa para o mundo todo. Cuida de servidores Linux, containers LXC, e de gatos que não saem de cima do teclado.